欢迎关注”生信修炼手册”!
拷贝数异常与疾病表型密切关联,当鉴定出患者的CNV之后,如何从其中挖掘出具有临床意义,即可能致病的CNV是数据挖掘中的关键一步。本文解读的文献标题如下

2012年发表在以下杂志
European Journal of Human Genetics
在文章中,提出了一套分析拷贝数重复的临床意义的操作规范,常规的判断CNV临床意义的方法如下
判断是遗传自父母还是新生的CNV变异,通常认为新生变异具有显著的临床意义,而遗传自父母的变异则为良性
和正常人群的CNV数据库进行比较,比如DGV或者实验室自建的正常对照样本的数据库,在正常人群中频率大于1%的CNV被认为是良性的CNV
通过这样的分类方法,仍然有非常大一部分CNV的临床意义不明确,而且随着研究的不断进步,发现第一条规则并不是非常适用,已经有文献支持有些遗传而来的CNV也具有致病性。而新生变异则为良性。为此,作者团队开发了一套新的判断CNV临床意义的分析体系,专门针对拷贝数重复进行分析。
构建了两个队列,一个用于实际分析,一个用于验证分析策略的可行性。选取了发育迟缓或者具有先天异常的患者,通过aCGH芯片来进行CNV分析,判断CNV临床意义的pipeline如下
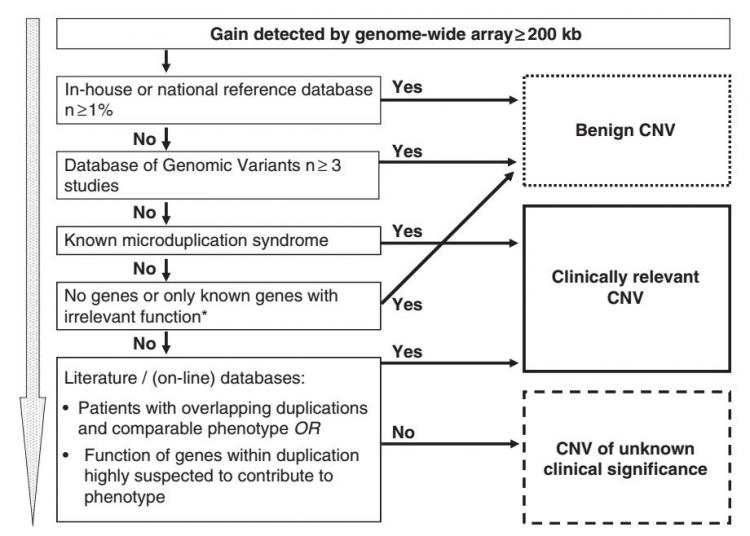
共分为5个大的步骤
第一步和自建或者公开的正常样本数据库比对,本文比对的是Low Lands consortium参照数据库,如果CNV在正常群体中频率大于1%, 则认为是良性的,当时该数据库包含了300个正常正常样本,理论上是采用3作为阈值的,考虑到部分样本和参照数据库有重叠,所以最终选择了4作为阈值,在4个以上样本中出现,认为是良性的,否则进行下一步判断
和DGV数据库进行比对,如果CNV在3个正常样本中出现,则认为是良性的,否则进行下一步判断
和已知的致病性CNV数据库比对,比如DECIPHER, 如果在数据库中说明该CNV是致病性的,且关联的表型和患者表型相同,直接就归为致病性,如果没有收录该CNV, 则进行下一步判断
看CNV覆盖区域是否包含基因,如果没有包含基因,或者包含的基因与疾病表型没有关联,则认为该CNV是良性的,否则进行到下一步判断
通过文献或者在线数据库的检索,如果有相关报道该CNV区域与疾病表型关联,则认为该CNV是具有临床意义的,否则临床意义不明确
通过这样的一套判断体系,两个队列的判读结果如下
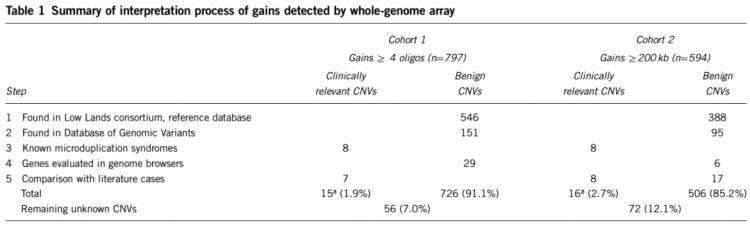
对第一个队列的CNV类型进行统计,汇总如下
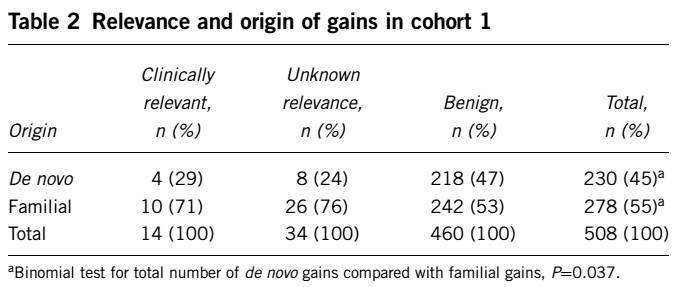
发现familial CNV比de novo CNV多,在致病性CNV中,familial CNV有10个,de novo有4个。大多数致病性CNV为遗传自父母的CNV;在良性CNV中,大部分de novo CNV为良性。
对不同临床意义的拷贝数重复的长度进行分析,结果如下
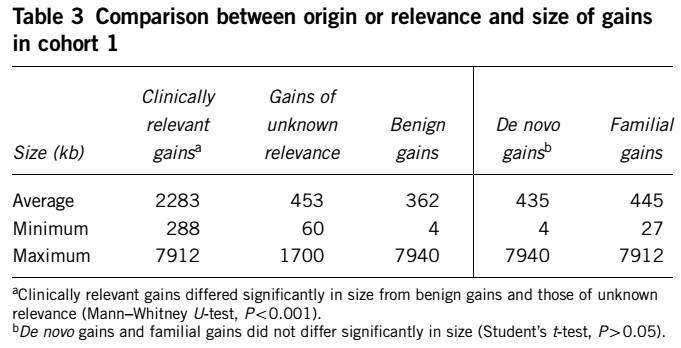
致病性CNV平均长度为2283bp, 良性和临床意义不明确的CNV长度则比较短,均值分别为362和453。而de novo和familial CNV长度则没有明显区别。
考虑到CNV的长度,测试了不同长度阈值的判断情况,结果如下
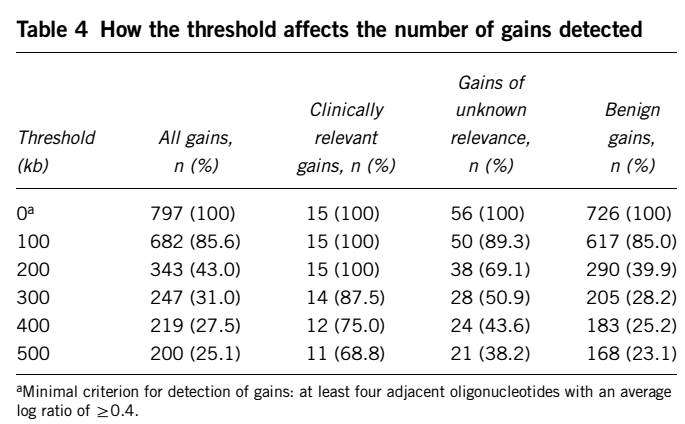
在200kb阈值时,15个致病性都检测到了,增加长度阈值,敏感性会降低;减小长度阈值,良性的CNV检测率变高,特异性降低,100kb时为617/682, 约为90.5%, 200kb时为290/343, 约为84.5%,为此,选择200kb作为长度过滤的阈值,在使用第二个队列评估时,增加了200kb的长度过滤。
本文通过对发育迟缓或者先天异常综合征的患者CNV进行分析,提出了一套分析拷贝数增加的临床意义的完整pipeline, 其中推荐使用200kb作为阈值,分析200kb以上的CNV。从判断的结果来看,也打破了de novo CNV高致病性高,遗传的CNV良性的假设。
在分析CNV的临床意义时,该文章的分析策略值得参考和借鉴。
·end·
—如果喜欢,快分享给你的朋友们吧—
扫描关注微信号,更多精彩内容等着你!











 京公网安备 11010802041100号
京公网安备 11010802041100号